我写这个主要是想把寝室的用电情况给保存下来,做一些分析统计之类的。代码运行在一台树莓派上面,树莓派连着校园网。
首先看看浏览器网页查询页面。
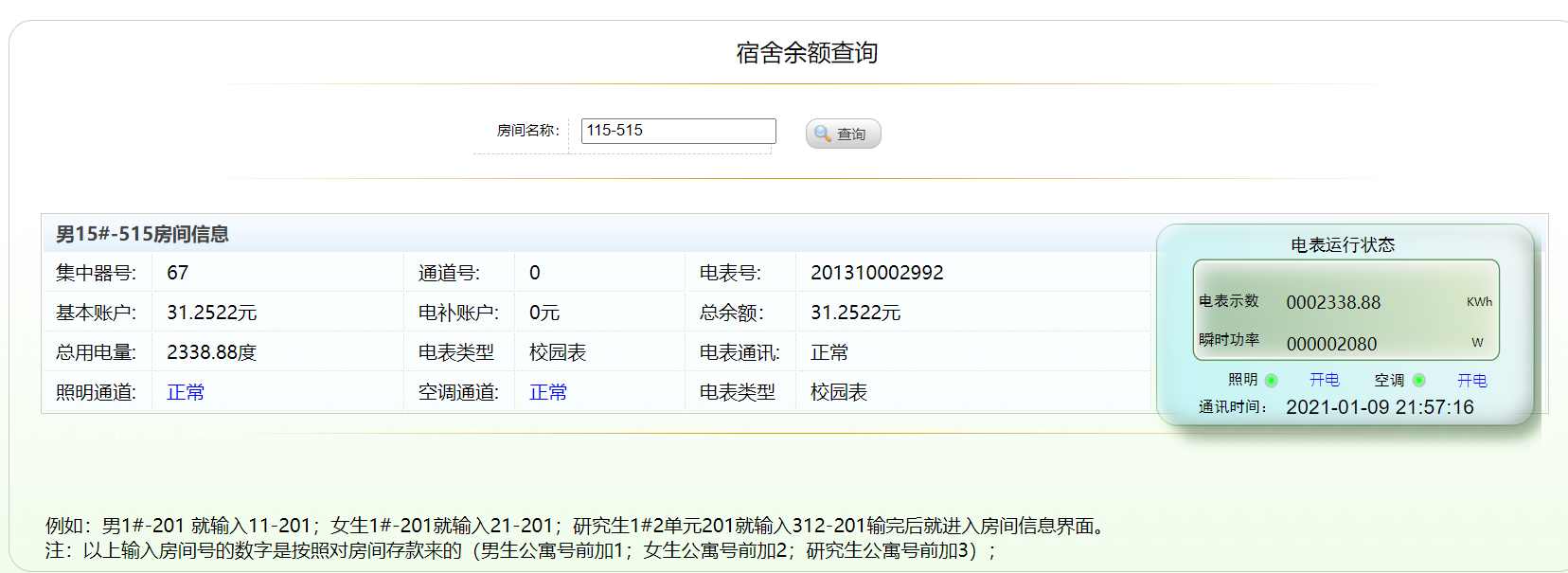
在写代码之前我们要先获取一些参数,而用这些参数可以让我们通过代码向服务器提交正确的请求信息从而获得服务器返回的数据。而与服务器交互有GET,POST,PUT,DELETE这四种方法,通常我们用POST来向服务器提交请求的信息。首先我们要知道需要POST的地址
获得post的地址和参数有两种方式,一种是通过查看网页源码,用谷歌浏览器的开发者工具分析信息,不过这种方式比较费时间。所以我介绍第二种方式,用抓包的方法。
首先我们要使用抓包软件来分析浏览器和服务器之间交换了什么信息,抓包软件Fiddler直接打开就开始抓包了,然后打开浏览器访问要抓包的网页。
Fiddler下载地址,文件来源于网络https://songzx.lanzoui.com/iaBrFk6mrsd
然后我们就会获得一些信息。
![]()
找到这种图标的,代表向服务器发送数据。点进去,再点inspectors
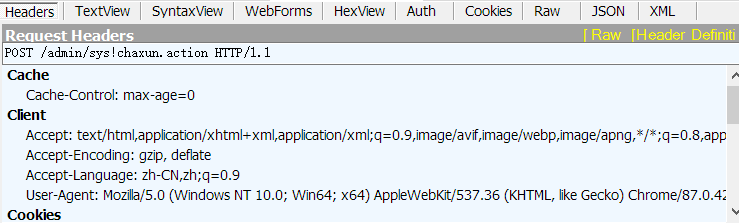
然后就个看到Headers里就是头文件的参数,后面要用到。
而SyntaxView里能看到发送的数据。也就是提交的表单信息。
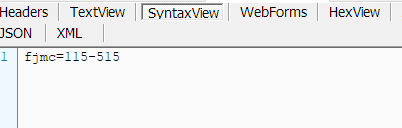
然后把相关的信息替换到代码里。
代码里相关库的导入和使用方法也可以查看最后的网址。
sudo pip install requests
sudo pip install beautifulsoup4
在POST服务器后获得的响应信息里可以发现这样的部分

这代表了标签为td,id属性为sjbzh的内容里就是我们想要的数据,我们通过使用soup.find_all(‘td’,id=”sjbzh”)来查找并提取出数值。其他的几个数值同理,只要提取出了数值就好处理了。
详细的修改可以看注释。
#coding=UTF-8
#!/usr/bin/python #可作为脚本写入开机自启动
import re #导入re库--正则表达式
import time
from bs4 import BeautifulSoup #导入BeautifulSoup
from distutils.filelist import findall
import requests #导入requests库
url="http://172.16.0.130:8808/admin/sys!chaxun.action" #把将要POST的地址赋值给url,该地址就是我们发送请求给服务器的地址。**********这个地址需要修改*******************
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
#请求的头文件*****************头文件需要修改*********************
formdata={
"fjmc":"115-515"
}#将要post的表单数据,也就是把这里的数据发送给服务器来获取到服务器的响应信息******************发送的数据需要修改****************
file_name = 'dianfei.txt' #在代码存在的文件夹新建个名为dianfei.txt的文本文件并赋给file_name
while(True): #循环获取信息**************************以下内容请根据实际网页响应的信息内容来修改*************************
response=requests.post(url,data=formdata,headers=headers) #发送post请求给服务器
#print(response.text)
soup = BeautifulSoup(response.text,"html.parser") #将服务器的响应信息赋给soup
power = (soup.find_all('text',id="Energy-1")[0].get_text()) #在信息里搜索text标签下id为Energy-1的内容并赋值给power,因为返回的内容为数组,所以后面加[0],以下同理。
electrical = (soup.find_all('text',id="Energy")[0].get_text())
now_time = (soup.find_all('text',id="text22056-1")[0].get_text())
balance = re.findall("\d+\.?\d*",(soup.find_all('td',id="sjbzh")[0].get_text())) #因为返回的值为字符串,里面有空格和汉字,所以用正则表达式提取字符串中的整数小数点以及后面的小数部分。
power= int(str(power)) #将字符串转为整数
electrical = float(str(electrical)) #将字符串转为小数,并去除例如字符串000012.33前面的四个0,以下同理。
balance=float(str(balance[0]))
#print(power)
#print(electrical)
#print(balance)
print("power:%dW electrical:%.2fKWh balance:%.4f time:%s"%(power,electrical,balance,now_time))
#打印读取到的各个数值
with open(file_name,'a') as file_obj: #以添加写入内容的形式打开文件
file_obj.write("power:%dW electrical:%.2fKWh balance:%.4f time:%s\n"%(power,electrical,balance,now_time))#将数据写入文件
time.sleep(195) #延时195秒后将再次读取,取这个时间是因为我发现用电数据的更新时间大概也就是195秒左右。
最后放一个用获取到的信息做的功率-时间图.

JavaScript教程https://www.w3school.com.cn/js/js_shiyong.asp
Python 爬虫利器一之 Requests 库的用法https://cuiqingcai.com/2556.html
Python爬虫(三)Requests库https://www.jianshu.com/p/fb6ee6cc5c1c
Python Requests库的基本使用https://www.cnblogs.com/youngleesin/p/11105132.html
Python获取网页指定内容(BeautifulSoup工具的使用方法)https://www.cnblogs.com/xisheng/p/9130156.html
Python 爬虫利器二之 Beautiful Soup 的用法https://cuiqingcai.com/1319.html
GET,POST,PUT,DELETE的区别https://blog.csdn.net/weixin_37509652/article/details/78542362
--------------------------------本教程由光阴似水1204原创,可自由转载,转载请附上本文网址,并标注来源。


文章评论
其实用浏览器的devtools就可以抓包了吧(
@小雅 确实可以,不过不太直观方便。