本帖旨在记录此次VITS模型的本地搭建训练过程及遇到问题的解决方法。(踩坑记录帖)
搭建过程全程参考此专栏文章:在本地(Windows/Linux)从零开始训练VITS中文AI语音模型到TTS推理的避坑教程指南
故此帖只会大致提到搭建流程,详细搭建步骤请看上面的专栏文章,若文章被删除或无法打开,点此处下载保存的PDF版本。
训练环境搭建过程
- 安装Conda
- VITS项目下载
- 安装MSVC及windows10 SDK或windows11 sdk取决于系统是10还是11。不安装SDK在下一步搭建环境中pip install中可能会报错。
- 搭建VITS环境
- 修改项目文件
- 准备数据集
- 预处理
- 开始训练
- TTS推理
下面将对第四步,第五步及第六步做部分解说,没说到的部分参考专栏教程即可。
在搭建VITS环境过程中,在安装依赖库上将版本号去除,可以会导致训练过程出错或安装依赖库出错的问题,这里可以将报错的库版本换成原先文档中设置的版本。也就是单独安装指定库,比如pip install pypinyin==版本号
修改项目文件
config.json文件部分参数解释(该内容为AI回答,不保证完全正确)
VITS模型的训练配置,各个参数含义如下:
log_interval: 训练过程中打印日志的间隔step数
eval_interval: 进行模型评估的间隔step数
seed: 随机种子数,保证结果可复现
epochs: 总训练epoch数
learning_rate: 初始学习率
betas: Adam优化器的动量参数
eps: Adam优化器中防止分母为0的epsilon值
batch_size: 训练batch大小
fp16_run: 是否使用混合精度训练
lr_decay: 学习率衰减率
segment_size: 输入波形截断长度
init_lr_ratio: 初始学习率占最大学习率的比例
warmup_epochs: warmup训练的epoch数
c_mel: mel频谱损失系数
c_kl: KL散度损失系数
其中需要注意的是,batch_size和segment_size的大小设置,sigment_size默认设置为8192,也就是说在数据集当中,音频长度大于8192毫秒的数据将不会用于训练。若不修改sigment_size的大小,则需要保持数据集的音频长度小于8秒,建议为2到8秒的长度。当然也可以将sigment_size修改为10240,这样可以使用长度小于10秒的音频。
但是需要注意的是,当修改sigment_size后,batch_size的参数需要改变,以防止爆显存。当sigment_size改大后,batch_size就要调小。可以这样理解,sigment_size是单个音频的长度,而batch_size是一次训练中用到的音频个数,这两个参数共同决定显存占用的大小。
我这里使用12G显存的显卡,设置的数据为sigment_size=10240,batch_size=20,训练中显存占用为11G左右。此外,sigment_size的大小最大就为10240,设置的再大也不起作用,音频的长度被限制在10秒以内,所以一定要确保音频的长度在10秒以内,超出10秒的是无效音频,会在训练中直接被抛弃,不参与训练。
准备数据集
我这里数据集处理的方法和上面专栏中不同,我的办法如下。
1、准备干净的人声音频。
可以使用ultimate vocal remover提取干净的人声,具体教程自行查找。
2、音频处理
使用AU或Audacity对音频进行剪辑及重采样处理,去除质量较差的语段,及将音频格式重采样为22050Hz,16位PCM。我这里使用Audacity软件。
3、提取字幕
我这里使用剪映提取字幕,具体方法使用剪映专业版自动生成字幕,然后对字幕进行合并。因为生成的字幕较短,需要将多个字幕合并成一句话。注意:字幕持续时间不要超过10秒,因为训练会自动抛弃超过10秒的音频。
注意:文本数据不要标错,数字使用中文代替,因为训练中会使用注音符号来代替实际的文字,比如“1234”这个数字会被转换为“一千两百三十四”这个发音,如果音频内容对不上,将会严重影响训练的模型效果。
4、数据标注
这里使用SoundLabel进行文本数据标注,虽然软件有小BUG,但是不算太影响使用。下载地址:https://github.com/kslz/SoundLabel
标注界面
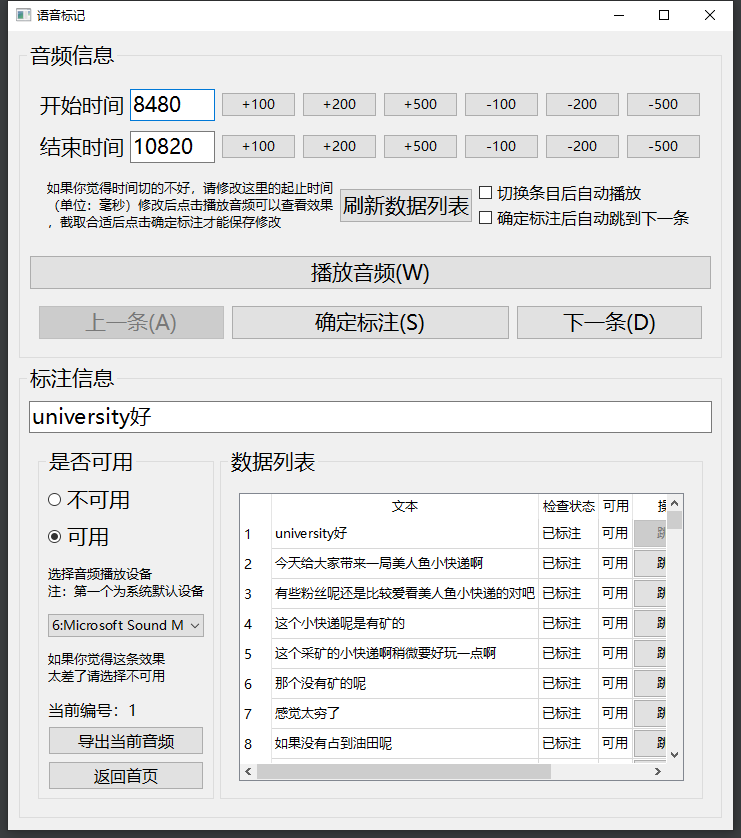
标注好后可以直接导出切片好的音频文件及文本文件。
注意,文本文件需要进行修改来适配VITS训练文本数据的格式。
使用文本编辑器的替换功能修改成如下格式即可。
![]()
数据集和验证集的分配及其他问题参考上面的专栏。
我使用RTX2060 12G显卡进行训练,一天大概能跑4.8万个迭代。官方文档中说训练50万个迭代效果显著,实测在20-30万个迭代后就有很不错的效果。
VITS训练日志格式(AI回答)
vits训练日志的参数分别代表着什么:INFO [2.1262433528900146, 2.822324275970459, 9.060163497924805, 19.967945098876953, 1.073176383972168, 1.1811175346374512, 188900, 0.0001244821996850592]
根据VITS的训练日志格式,这组参数的含义如下:
2.1262433528900146: 生成器损失(loss_gen)
2.822324275970459: 判别器损失(loss_disc)
9.060163497924805: mel频谱损失(loss_mel)
19.967945098876953: 时长预测损失(loss_dur)
1.073176383972168: Kullback-Leibler散度损失(loss_kl)
1.1811175346374512:特征匹配损失(loss_fm)
188900: 训练步数(global_step)(迭代次数)
0.0001244821996850592: 学习率(lr)


文章评论